Model based Planning With Discrete and Continuous Actions
1 Introduction
Planning actions in order to accomplish a specific goal is a challenge of fundamental interest in artificial intelligence. One of the main paradigms for addressing planning problems is model-free reinforcement learning (RL), a general approach where an agent samples actions according to an internal policy and then adjusts the policy as a function of the reward it receives for different actions. This method has the advantage of making minimal assumptions about the task at hand and can learn complex policies using only the raw state representation and a scalar reward signal. In recent years model-free RL using deep neural network controllers has proven successful for a number of applications including Atari games
(Mnih et al., 2015), robotic manipulation (Gu et al., 2016), navigation and reasoning tasks (Oh et al., 2016), and machine translation (Ii et al., 2014). However, it also suffers from several limitations, including high sample complexity (Schulman et al., 2015a)
, unstable training due to a difficult temporal credit assignment problem and non-stationary input distribution, and sensitivity to hyperparameters and implementatation details
(Henderson et al., 2017).
Model-based planning assumes the existence of a forward model of the environment which can predict how the world will evolve in response to different actions. Actions can then be planned by using this forward model to select a sequence of actions which will take the agent from its current state to a desired goal state or maximize rewards along a trajectory. If the actions are discrete, tree search methods can be used to search over different action sequences and evaluate their quality using the forward model. Expanding a full tree is often computationally infeasible, hence stochastic approximations are often used to only expand its most promising branches (Coulom, 2007)
. If actions are continuous, using differentiable forward models is particularly appealing as they provide gradients which define a direction of improvement for a sequence of actions. These gradients with respect to plans make it possible to do "planning by backprop", directly optimizing a sequence of actions by backpropagating gradients from a goal state through a learned model to update a plan.
Learning a forward model typically has lower sample complexity than model-free RL due to the rich information content of its high-dimensional error signal, and can in some cases be done using observational data. This can provide a way to derive plans in a way that is sample efficient with regard to environment interactions. When learning policies using a fast simulator, it is possible to try many actions within the simulated environment since they carry little computational cost and mistakes do not affect the real world. However, when training policies in real environments, minimizing the number of interactions with the environment can often be crucial, as performing actions (such as driving a vehicle or moving a robot) can be orders of magnitude slower than performing an update of the policy model, and mistakes can carry real-world costs.
In this work, we show that planning with discrete and continuous actions using a learned forward model can be done using the same unified gradient-based approach. By using a simple reparameterization of discrete action vectors in the simplex combined with the addition of input noise when training an action-conditional forward model, we obtain a modified loss function in which it is easy to optimize discrete actions by gradient descent. We show experimentally that optimal control methods can then be effectively used in discrete action spaces, and are able to achieve similar performance to a strong tree search baseline while being straightforward to parallelize. We also show that it is possible to further speed up planning at inference time by training a feedforward policy network to imitate high-quality trajectories generated by gradient descent using the learned forward model and states it was trained on. This can be done using only trajectories synthesized by the forward model and does not require additional environment interaction. We additionally introduce a challenging task which requires jointly optimizing discrete and continuous actions, and show that our approach is able to learn behaviors which account for complex environment dynamics, outperforming a model-free approach.
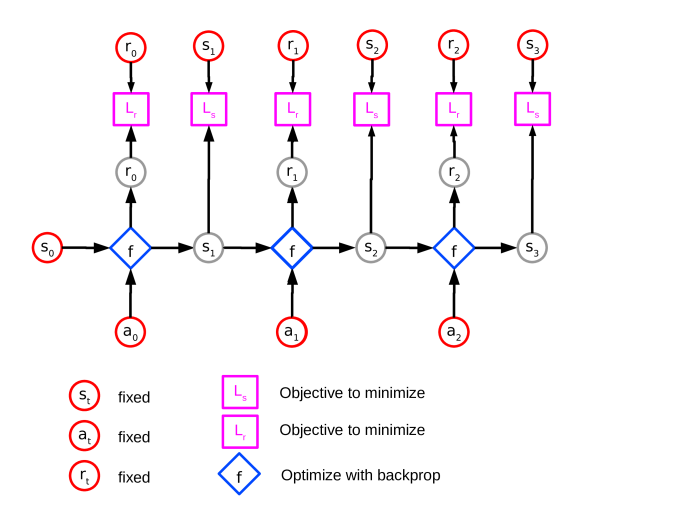
2 Planning with Forward Models
The discrete-time Markov Decision Process (MDP)
(Bellman, 1957) is a widely used model for decision making and planning. In this framework, at every time step an agent is presented with a representation of the state of the environment, performs an action , and receives a reward . The next state is then given as some unknown function of the current state and action, and the process is repeated.
Planning with a forward model requires first estimating both the transition function and the reward function, using the agent's own experience or observational data. More precisely, the agent learns a transition model
which predicts the next state and a reward model which predicts the next reward by minimizing the following loss function over a dataset of trajectories indexed by :
where the per-sample loss is given by:
Here and are loss functions which are appropriate to the states and rewards being considered, we use mean-squared error in this work but this choice is dependent on the task. In practice, and may share parameters, for example by sharing the same encoding of the state and action and mapping it to a next state and reward respectively. It can also be beneficial to replace true inputs beyond the initial state by the predicted inputs during training, as shown in Figure 1. This has the effect of making the model more robust by training it to account for its future prediction errors. We use this setup in all our experiments.
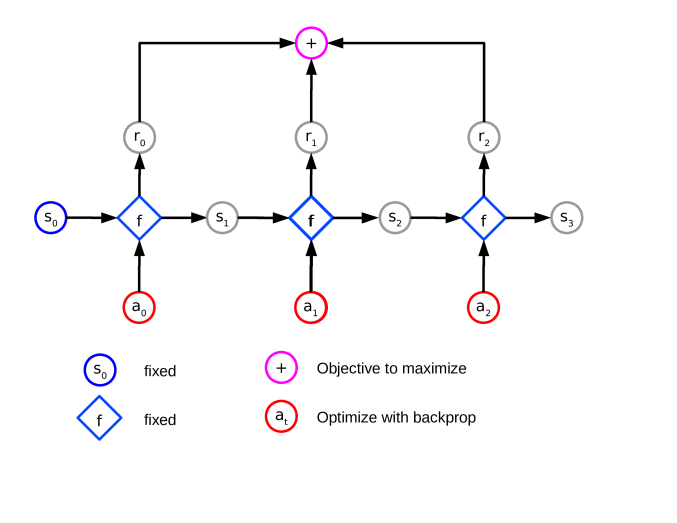
After training, given some current state the agent can use the forward model to plan actions with the goal of maximizing the sum of future rewards. This is done by solving the following optimization problem:
where and . If is a neural network model and the input action space is continuous, this optimization procedure can be done using gradient descent by straightforwardly applying the backpropagation rule which computes the gradients with respect to both the weights and the inputs. Starting from a randomly initialized sequence of action vectors, the loss function can be minimized by performing gradient descent in the input action space. One can also repeat this process (in sequence or in parallel) for multiple initially sampled sequences of action vectors and pick the one with the highest estimated reward. This can be useful if the initial action trajectory is of low quality and there is no direction for it to improve, and can be viewed as performing multiple action rollouts, correcting them through gradient descent and keeping the best one.
3 Planning with Discrete Actions
When the action space is discrete, input actions are typically encoded as one-hot vectors. In this case, there is no guarantee that the result of the above optimization procedure will constitute a valid input action sequence. We propose two modifications to remedy this issue. The first is to restrict the set of valid actions to the simplex. Let be a discrete set of actions encoded as one-hot vectors. The task is then to find:
Instead of requiring that the actions lie on the hypercube, we can relax the constraints and require that they lie on the simplex . Note that the points on the simplex can be written as:
where represents the softmax function. The relaxed optimization problem can thus be reformulated as:
A sequence of tokens can thus be chosen by minimizing the above loss function, quantizing each to the closest one-hot vector, and mapping back to the corresponding token.
This reformulation restricts the actions from the entire space to the simplex, however optimizing the actions by gradient descent may still yield points which are in the interior of the simplex rather than its vertices which are the one-hot vectors. Our second modification is to modify the loss surface by adding Gaussian noise to the action vectors during training. We then optimize the following loss function when training the forward model:
This has the effect of making the loss surface more convex around the action vectors. To see why, observe that the modified per-sample loss
can be rewritten as:
The probability mass is highest at
, which corresponds to the one-hot vector encoding , and becomes progressively lower as we move further from the one-hot vector. This means that the model is presented with more points close to the one-hot vector during training, which will cause it to lower the loss surface at those points around that vector during its weight update. Points further from the one-hot vector will be presented less often, which means that the loss surface will be lowered less and less as we get further away from the one-hot vector which encodes . This results in a smoothing of the loss surface around the one-hot vectors encoding each of the actions, forming attractors which are easy to find during optimization.
 |  |  |  |
This method for inferring actions, which we here refer to as the Gradient-Based Planner, is detailed in Algorithm 1
. In all our experiments, we set the variance of the added noise to
. To illustrate this effect we provide visualizations using a simple example. Consider the simple one-step MDP given by:
where . The optimal action will be if and if , and both actions become increasingly equivalent as gets closer to zero. We trained two networks to predict the reward from states and actions, using data where , was or with equal probability and defined as above. One network was trained with Gaussian noise added to the input
and the other was trained normally. Both networks were 2-layer MLPs with 100 hidden units and ReLU activations and were trained with Adam
(Kingma & Ba, 2014). In Figure 3 we plot the predicted cost (negative reward) for different values of for both networks. Note that both networks produce a similar prediction at the action values which are seen during training. However, the cost surface between the action values and for the network trained without noise exhibits local minima and maxima, whereas the predicted cost surface of the network trained with input noise is smooth and monotonically decreases from the suboptimal action to the optimal one. This suggests that for a fixed state , if we sample a random value of and follow the gradient along the cost surface, the result will be more likely to be the optimal action in the case of the network trained with noise than the network trained without noise.
4 Self-Teaching a Policy Network
Gradient-based planning requires solving an iterative optimization procedure every time an action or sequence of actions is required, which may be too slow for certain applications. It may therefore be desirable to train a policy network which can quickly map states to actions at test time while still requiring few interactions with the environment.
We propose to do this by self-teaching a policy network using the learned model together with the dataset that the environment model was trained on. This dataset consists of states, actions and rewards observed or experienced by the agent. We can collect the states from this dataset and then use the learned environment model to infer what optimal actions would have been for each of these states, together with how states would evolve in response to these actions. This creates a new dataset of state-action pairs which can be used to train a policy network mapping states to actions inferred by the learned model in a supervised fashion. Note that this does not require any additional interactions with the environment as we only use the dataset used to train the forward model. We refer to this approach, shown in Algorithm 2, as DistGBP for Distilled Gradient-Based Planner. We also note that such a policy network could be used to produce the initial rollouts in Algorithm 1, which would then be further refined by gradient descent.
Input: Current state , trained models .
Input: Number of rollouts , timesteps to unroll , gradient steps .
Set .
for to do
Sample
for to do
for to do
endfor
for to do
endfor
endfor
.
endfor
Return: Action sequence and state trajectory for which is largest.
Input: Dataset used to train models .
Build demonstration dataset:
for to do
Sample
GBP ( )
for to do
endfor
endfor
Train policy model:
repeat
Sample
Compute policy loss
Update .
until converged
5 Related Work
The idea of planning a sequence of continuous actions by backpropagating along a policy trajectory has existed since the 1960's (Kelley, 1960; Dreyfus, 1962). These methods were applied to settings where the state transition dynamics of the environment were known analytically and backward derivatives could be computed exactly, such as planning flight paths. Later works (Schmidhuber, 1990; Jordan & Rumelhart, 1992) explored the idea of backpropagating through learned, approximate forward models of the environment to plan actions for tasks such as parking a vehicle (Nguyen & Widrow, 1990).
In recent years there have been several works revisiting model-based planning in the context of modern neural networks, for example vehicle navigation (Hamrick et al., 2017) or robotics (Todorov & Li, 2005; Abbeel et al., 2007; Todorov et al., 2012; Kumar et al., 2016). The work of (Weber et al., 2017) used a learned model of the environment to plan sequences of discrete actions using imagined rollouts performed by a separate policy network, which are then encoded and fed as additional context to a model-free policy network. Our approach also uses discrete actions and a learned environment model, but differs in that we do not use reinforcement learning and instead correct initial random rollouts through gradient descent, which can then either be executed or used as training trajectories for a policy network.
There has been recent work in continuous relaxations of discrete random variables
(Maddison et al., 2016; Jang et al., 2017), that also uses a softmax to form a continuous approximation to a discrete set. These methods use a temperature parameter to anneal from the continuous formulation to the discrete one, which has the effect of pushing solutions towards the vertices of the simplex. In our approach we change the shape of the loss function of the forward model during training to have attractors at the vertices, rather than using a regularization term when optimizing the actions.
Our approach to training a policy network is related to the Dyna architecture introduced in (Sutton, 1991), which also uses a learned model of the environment to perform policy updates without needing to interact with the environment. This was introduced in the context of
-learning in the tabular setting. Our policy updates are related to imitation learning
(Pomerleau, 1991) where an agent is trained to imitate trajectories provided by an expert; here the training trajectories are provided by our gradient-based planning algorithm. The work of (Guo et al., 2014) used Monte-Carlo Tree Search (MCTS) together with an Atari simulator to generate high-quality action sequences for different games which were then used to train an agent through imitation learning. This is related to our approach which also uses a slower planning method to generate trajectories offline which are then used to train a fast policy network. However, we use a learned model of the environment rather than a ground-truth simulator to generate trajectories, and our method of inferring action sequences is different. Also related are policy distillation methods where a complex neural network is approximated by a simpler and typically faster one (Hinton et al., 2015; Rusu et al., 2015). Here, we train a network to approximate the results of a planning procedure rather than the output of another network.
6 Experiments
We tested our approach on two domains: one with a purely discrete action space, and one where the actions space contains both discrete and continuous actions. In these experiments, we evaluate different methods according to three measures: how well the method solves the task, the number of interactions with the environment needed to achieve good performance, and the speed at inference time. For each experiment, we evaluate both the gradient-based planner described in Algorithm 2, which we denote GBP , and the policy network trained to imitate trajectories from this model as described in Section 4, which we call DistGBP .
 |  |  |  |  |  |
6.1 Gridworld Domains
The first task we evaluated our approach on was the Gridworld domain introduced in (Tamar et al., 2016). In these tasks, an agent is placed in a map and must make its way to a goal while avoiding obstacles. The MDP is structured as follows: states are represented by -channel images of size or where the first channel represents obstacle locations, the second the goal location and the third the agent's current location (examples are shown in Figure 4). The agent can perform 4 actions: move and receives a reward of for reaching the goal, a reward of for hitting an obstacle (after which the episode ends), and a reward of for every other timestep to encourage it to reach the goal quickly. The test set consists of maps which are different from those used for training.
For each gridworld size we trained an action-conditional forward model using 10K episodes where the agent followed a uniform random policy over actions. The architecture consisted of a convolutional encoder whose output was combined with a learned embedding of the action vector, which was then fed to a convolutional decoder to predict the next state, as well as a second convolutional network followed by a fully-connected layer with scalar output and hyperbolic tangent to predict the reward. We used 16 feature maps for all convolutional layers and 16 hidden units for the fully-connected layers. All networks were trained with Adam (Kingma & Ba, 2014) using a learning rate of 0.001.
As a first experiment, we compared GBP to Monte-Carlo Tree Search (MCTS) (Coulom, 2007). MCTS is a discrete planning algorithm where a search tree is selectively expanded in directions which are likely to be most promising, as determined by simulated playouts from the leaves of the tree. This method can be shown to achieve optimal performance given a perfect environment model and enough simulated rollouts, and has been successfully used in contexts such as games (Silver et al., 2016)
, combinatorial optimization
(Sabharwal et al., 2012) and scheduling (Cazenave et al., 2009). As a simulator, we used the same learned model of the environment as for GBP . Both methods can trade accuracy for computation time by performing larger numbers of rollouts.
Figure 5 shows the tradeoff between accuracy and computation time for GBP and MCTS, measured in the number of forward and backward passes through the environment model. For MCTS we computed performance using rollouts, for GBP we used 10 gradient steps and rollouts. All results are averaged over 500 trials. We see that both methods require a similar number of passes through the model to achieve a given level of accuracy, which suggests that GBP can discover sequences of discrete actions through gradient descent of similar quality to those discovered by a strong discrete planning algorithm. We also note that GBP can be easily parallelized on a GPU by treating different rollouts as samples in a minibatch, which allows us to increase the accuracy at little computational cost, whereas MCTS is more challenging to parallelize due to the sequential nature of the updates to the tree policy and the variable length of simulated playouts (Segal, 2011; Browne et al., 2012).
 |  |
We next compared different approaches in terms of best accuracy, planning time and number of environment interactions, shown in Table 1. We report the TRPO results of (Tamar et al., 2016), which use a CNN model trained with Trust Region Policy Optimization (Schulman et al., 2015b) together with a curriculum whereby easier maps (with the goal placed close to the agent) are shown early in training and harder maps are shown later. For the maps we also include results using the OpenAI Baselines (Brockman et al., 2016) implementation of TRPO using the same architecture since the published results do not include the number of training steps. To train the DistGBP , we generated 24K trajectories using GBP for the maps and 75K trajectories for the
maps, and trained a policy model with supervised learning. The policy model for
maps was a 2-layer CNN with 16 feature maps, followed by a fully-connected layer with 16 hidden units; for the maps we used a 3-layer CNN with 64 feature maps and 64 hidden units in the fully-connected layer.
| Map | Method | Acc. | Time (s) | Env. Steps |
| TRPO* | 86.9 | - | ||
| TRPO (ours) | 82.4 | 22M | ||
| GBP | 94.0 | 0.03 | 54K | |
| DistGBP | 91.4 | 54K | ||
| GBP (no noise) | 25.6 | 0.03 | 54K | |
| TRPO* | 33.1 | 3M | ||
| GBP | 66.4 | 0.51 | 110K | |
| DistGBP | 52.6 | 110K | ||
| GBP (no noise) | 07.8 | 0.51 | 110K |
Both implementations of model-free TRPO achieve good performance on the gridworld task and are able to perform fast inference 1 1 1Since both models have the same architecture, we report the same inference time for the published results as for our model. . We found that our TRPO model only achieved comparable performance to the published TRPO model after a large number of steps (22 million). The other methods use a learned environment model, which is here done using comparably fewer environment interactions. This is sufficient to achieve good performance for GBP given enough planning time. Our self-taught policy network is furthermore able to achieve comparable performance while being as fast as the reactive policy at inference time and using few environment interactions. Furthermore, it does not require a curriculum as it is trained in a supervised manner on trajectories that are optimized over many timesteps and thus capture longer-term dependencies between actions and rewards.
The gridworld task is more challenging as it requires finding longer paths. Here we increased the unrolling depth of the forward model from 10 to 15 in order to capture longer-term dependencies and increased the number of rollouts to 1000. GBP here performs significantly better than the model-free method at the cost of additional computation time at inference. DistGBP is also able to perform significantly better than TRPO, while having the same speed and using fewer environment interactions.
We also include results for forward models trained without noise. For both Gridworld datasets, using a model trained without noise causes a substantial decrease in performance. Figure 6 shows action vectors optimized with backprop for the same set of input states using a forward model trained with and without noise. In the first case most of the inferred action vectors are close to the one-hot vectors, which are consistent with the input distribution the model was trained on. In the second case, the solution does not resemble any input seen during training which causes the model to produce an incorrectly large reward estimate, in the same way as adversarial examples can cause a model to predict an incorrect image with high confidence.
 |  |  |  |  |  |  |  |  |  |
6.2 Spaceship Domain
Having validated that our approach can indeed be used to optimize discrete actions by gradient descent, we next tested it on a domain where the action space contains both discrete and continuous actions. In settings with both types of actions, tree search methods such as MCTS cannot be applied as the search space is effectively infinite and unmodified optimal control methods cannot be straightforwardly applied due to the presence of discrete actions. We used a spaceship domain inspired by recent works (Hamrick et al., 2017; Pascanu et al., 2017), where the agent must pilot a spaceship in the presence of planets and their gravitational forces. In our task, the agent must pilot its ship to make contact with one of three different colored waypoints using its thrusters and emit a colored signal the same color as the waypoint. Applying thrust is a continuous action while emitting a colored signal is a discrete action, with one possibity for each color in addition to no signal. Furthermore, the agent must avoid getting too close to the planet's gravitational field which may cause it to crash into the planet.
The agent receives a reward of for emitting the same color as a waypoint it touches, a reward of emitting a different color, a reward of for emitting a color elsewhere than at a waypoint, and a reward of for coming into contact with a planet. At every time step, the agent's position and velocity are updated as a function of the thrust vector and the gravitational force applied by the planet using the Euler method (details are provided in the Appendix). The agent must therefore learn to navigate to a waypoint while avoiding the planets (which requires optimizing continuous actions) and execute the correct discrete action once it gets there. Each episode is of length 80 time steps and the agent keeps receiving rewards (positive or negative) until the end of the episode.
 |  |
We compared three approaches: GBP , DistGBP , and an Advantage Actor-Critic (A2C) agent, a state-of-the-art model-free method (Mnih et al., 2016)
. We trained a forward model on 10K episodes of the agent following a random policy where its continuous thrusters were fired according to an isotropic Gaussian distribution and its discrete actions followed a uniform categorical one (architecture and training details are in the Appendix). The A2C agent consisted of a 4-layer actor network and a 4-layer critic network, each with 512 hidden units and ReLU activations. The actor network output two heads: a categorical distribution over discrete actions and a 2D diagonal gaussian distribution over continuous actions. We trained the A2C model with 16 parallel workers and optimized the learning rate over the range
and the entropy regularization coefficient over . The DistGBP policy network had the same architecture as the actor network in the A2C model.
Average rewards for the policies learned by the different models as well as a random policy are shown in Table 2. Videos of the the DistGBP agent at can be seen at https://youtu.be/9Xh2TRQ_4nM and the A2C agent at https://youtu.be/XLdme0TTjiw. The A2C model is able to learn a policy where it moves away from the planet, which enables it to achieve a significant improvement in average reward over the baseline. However, it does not learn to navigate towards the waypoints or use its signals to collect positive rewards and only tries to minimize negative reward by avoiding the planet's gravity. The DistGBP agent significantly outperforms the A2C model in terms of average reward, and learns interesting behaviors such as moving away from the planet, moving towards the waypoints when it gets sufficiently close and turning the right color when it reaches them. This requires learning dependencies between continuous and discrete actions, since turning the wrong color when touching a waypoint incurs a negative reward. It is also able to accurately compensate for the gravitational pull of the planet when it touches a waypoint, applying the correct thrust vector depending on the planet size and location to remain stationary and thus maximize its reward. This indicates that the policy network is able to leverage the environment dynamics learned by the forward model, which are themselves reflected in the state-action trajectories the policy network is trained on. Note that GBP performs similarly to DistGBP in terms of reward, but has considerably higher inference time.
7 Conclusion
In this work, we have introduced a novel method for performing gradient-based planning in discrete action spaces and shown that it can effectively be used both in discrete action settings as well as settings which combine discrete and continuous actions where other methods are not easily applicable. Furthermore, we have shown that the iterative procedure required to obtain high-quality action sequences through gradient descent is not an obstacle for real-time applications, as the planning policy can be approximated by a fast feedforward network trained to imitate optimal trajectories produced by the model. Taken together, these steps provide a general approach for deriving agents capable of executing sophisticated policies in real time which do not require large amounts of environment interaction.
References
- Abbeel et al. (2007) Abbeel, Pieter, Coates, Adam, Quigley, Morgan, and Ng, Andrew Y. An application of reinforcement learning to aerobatic helicopter flight. Advances in neural information processing systems, 19:1, 2007.
- Bellman (1957) Bellman, Richard. Dynamic Programming. Dover Publications, 1957. ISBN 9780486428093.
- Brockman et al. (2016) Brockman, Greg, Cheung, Vicki, Pettersson, Ludwig, Schneider, Jonas, Schulman, John, Tang, Jie, and Zaremba, Wojciech. Openai gym, 2016.
- Browne et al. (2012) Browne, Cameron, Powley, Edward, Whitehouse, Daniel, Lucas, Simon, Cowling, Peter I., Tavener, Stephen, Perez, Diego, Samothrakis, Spyridon, Colton, Simon, and et al. A survey of monte carlo tree search methods. IEEE TRANSACTIONS ON COMPUTATIONAL INTELLIGENCE AND AI, 2012.
- Cazenave et al. (2009) Cazenave, Tristan, Balbo, Flavien, and Pinson, Suzanne. Using a monte-carlo approach for bus regulation. 10 2009.
- Coulom (2007) Coulom, Rémi. Efficient selectivity and backup operators in monte-carlo tree search. In Proceedings of the 5th International Conference on Computers and Games, CG'06, pp. 72–83, Berlin, Heidelberg, 2007. Springer-Verlag. ISBN 3-540-75537-3, 978-3-540-75537-1.
- Dreyfus (1962) Dreyfus, Stuart. The numerical solution of variational problems. Journal of Mathematical Analysis and Applications, 5(1):30 – 45, 1962. ISSN 0022-247X. doi: http://dx.doi.org/10.1016/0022-247X(62)90004-5. URL http://www.sciencedirect.com/science/article/pii/0022247X62900045.
- Gu et al. (2016) Gu, Shixiang, Holly, Ethan, Lillicrap, Timothy P., and Levine, Sergey. Deep reinforcement learning for robotic manipulation. CoRR, abs/1610.00633, 2016. URL http://arxiv.org/abs/1610.00633.
- Guo et al. (2014) Guo, Xiaoxiao, Singh, Satinder, Lee, Honglak, Lewis, Richard L, and Wang, Xiaoshi. Deep learning for real-time atari game play using offline monte-carlo tree search planning. In Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N. D., and Weinberger, K. Q. (eds.), Advances in Neural Information Processing Systems 27, pp. 3338–3346. Curran Associates, Inc., 2014.
- Hamrick et al. (2017) Hamrick, Jessica, Ballard, Andrew, Pascanu, Razvan, Vinyals, Oriol, Heess, Nicolas, and Battaglia, Peter. Metacontrol for adaptive imagination-based optimization. ICLR 2017, 2017.
- Henderson et al. (2017) Henderson, Peter, Islam, Riashat, Bachman, Philip, Pineau, Joelle, Precup, Doina, and Meger, David. Deep reinforcement learning that matters. CoRR, abs/1709.06560, 2017.
- Hinton et al. (2015) Hinton, Geoffrey E., Vinyals, Oriol, and Dean, Jeffrey. Distilling the knowledge in a neural network. CoRR, abs/1503.02531, 2015.
- Ii et al. (2014) Ii, Alvin C. Grissom, He, He, Morgan, John, and III, Hal Daume. Don't until the final verb wait: Reinforcement learning for simultaneous machine translation. In In Proceedings of EMNLP, 2014.
- Jang et al. (2017) Jang, Eric, Gu, Shixiang, and Poole, Ben. Categorical reparameterization with gumbel-softmax. 2017. URL https://arxiv.org/abs/1611.01144.
- Jordan & Rumelhart (1992) Jordan, Michael I. and Rumelhart, David E. Forward models: Supervised learning with a distal teacher. Cognitive Science, 16(3):307 – 354, 1992. ISSN 0364-0213. doi: http://dx.doi.org/10.1016/0364-0213(92)90036-T. URL http://www.sciencedirect.com/science/article/pii/036402139290036T.
- Kelley (1960) Kelley, Henry. An on-line algorithm for dynamic reinforcement learning and planning in reactive environments. 30(10):947–954, 1960. URL http://arc.aiaa.org/doi/abs/10.2514/8.5282?journalCode=arsj.
- Kingma & Ba (2014) Kingma, Diederik P. and Ba, Jimmy. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014. URL http://arxiv.org/abs/1412.6980.
- Kumar et al. (2016) Kumar, Vikash, Todorov, Emanuel, and Levine, Sergey. Optimal control with learned local models: Application to dexterous manipulation. In Robotics and Automation (ICRA), 2016 IEEE International Conference on, pp. 378–383. IEEE, 2016.
- Langley (2000) Langley, P. Crafting papers on machine learning. In Langley, Pat (ed.), Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stanford, CA, 2000. Morgan Kaufmann.
- Maddison et al. (2016) Maddison, Chris J., Mnih, Andriy, and Teh, Yee Whye. The concrete distribution: A continuous relaxation of discrete random variables. CoRR, abs/1611.00712, 2016. URL http://arxiv.org/abs/1611.00712.
- Mnih et al. (2015) Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Rusu, Andrei A., Veness, Joel, Bellemare, Marc G., Graves, Alex, Riedmiller, Martin, Fidjeland, Andreas K., Ostrovski, Georg, Petersen, Stig, Beattie, Charles, Sadik, Amir, Antonoglou, Ioannis, King, Helen, Kumaran, Dharshan, Wierstra, Daan, Legg, Shane, and Hassabis, Demis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, February 2015. ISSN 0028-0836. doi: 10.1038/nature14236. URL http://dx.doi.org/10.1038/nature14236.
- Mnih et al. (2016) Mnih, Volodymyr, Badia, Adrià Puigdomènech, Mirza, Mehdi, Graves, Alex, Lillicrap, Timothy P., Harley, Tim, Silver, David, and Kavukcuoglu, Koray. Asynchronous methods for deep reinforcement learning. CoRR, abs/1602.01783, 2016.
- Nguyen & Widrow (1990) Nguyen, Derrick and Widrow, Bernard. Neural networks for control. chapter The Truck Backer-upper: An Example of Self-learning in Neural Networks, pp. 287–299. MIT Press, Cambridge, MA, USA, 1990. ISBN 0-262-13261-3. URL http://dl.acm.org/citation.cfm?id=104204.104216.
- Oh et al. (2016) Oh, Junhyuk, Chockalingam, Valliappa, Singh, Satinder P., and Lee, Honglak. Control of memory, active perception, and action in minecraft. CoRR, abs/1605.09128, 2016. URL http://arxiv.org/abs/1605.09128.
- Pascanu et al. (2017) Pascanu, Razvan, Li, Yujia, Vinyals, Oriol, Heess, Nicolas, Buesing, Lars, Racanière, Sébastien, Reichert, David P., Weber, Theophane, Wierstra, Daan, and Battaglia, Peter. Learning model-based planning from scratch. CoRR, abs/1707.06170, 2017.
- Pomerleau (1991) Pomerleau, Dean A. Efficient training of artificial neural networks for autonomous navigation. Neural Computation, 3:97, 1991.
- Rusu et al. (2015) Rusu, Andrei A., Colmenarejo, Sergio Gomez, Gülçehre, Çaglar, Desjardins, Guillaume, Kirkpatrick, James, Pascanu, Razvan, Mnih, Volodymyr, Kavukcuoglu, Koray, and Hadsell, Raia. Policy distillation. CoRR, abs/1511.06295, 2015.
- Sabharwal et al. (2012) Sabharwal, Ashish, Samulowitz, Horst, and Reddy, Chandra. Guiding combinatorial optimization with uct. In Beldiceanu, Nicolas, Jussien, Narendra, and Pinson, Éric (eds.), Integration of AI and OR Techniques in Contraint Programming for Combinatorial Optimzation Problems, pp. 356–361, Berlin, Heidelberg, 2012. Springer Berlin Heidelberg.
- Schmidhuber (1990) Schmidhuber, Jurgen. An on-line algorithm for dynamic reinforcement learning and planning in reactive environments. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), 1990.
- Schulman et al. (2015a) Schulman, John, Levine, Sergey, Abbeel, Pieter, Jordan, Michael I., and Moritz, Philipp. Trust region policy optimization. In Bach, Francis R. and Blei, David M. (eds.), ICML, volume 37 of JMLR Workshop and Conference Proceedings, pp. 1889–1897. JMLR.org, 2015a. URL http://dblp.uni-trier.de/db/conf/icml/icml2015.html#SchulmanLAJM15.
- Schulman et al. (2015b) Schulman, John, Levine, Sergey, Moritz, Philipp, Jordan, Michael I., and Abbeel, Pieter. Trust region policy optimization. CoRR, abs/1502.05477, 2015b.
- Segal (2011) Segal, Richard B. On the scalability of parallel uct. In van den Herik, H. Jaap, Iida, Hiroyuki, and Plaat, Aske (eds.), Computers and Games, pp. 36–47, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg. ISBN 978-3-642-17928-0.
- Silver et al. (2016) Silver, David, Huang, Aja, Maddison, Chris J., Guez, Arthur, Sifre, Laurent, van den Driessche, George, Schrittwieser, Julian, Antonoglou, Ioannis, Panneershelvam, Veda, Lanctot, Marc, Dieleman, Sander, Grewe, Dominik, Nham, John, Kalchbrenner, Nal, Sutskever, Ilya, Lillicrap, Timothy, Leach, Madeleine, Kavukcuoglu, Koray, Graepel, Thore, and Hassabis, Demis. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587):484–489, January 2016. doi: 10.1038/nature16961.
- Sutton (1991) Sutton, Richard S. Dyna, an integrated architecture for learning, planning, and reacting. SIGART Bull., 2(4):160–163, July 1991. ISSN 0163-5719. doi: 10.1145/122344.122377.
- Tamar et al. (2016) Tamar, Aviv, Levine, Sergey, and Abbeel, Pieter. Value iteration networks. CoRR, abs/1602.02867, 2016. URL http://arxiv.org/abs/1602.02867.
- Todorov & Li (2005) Todorov, Emanuel and Li, Weiwei. A generalized iterative lqg method for locally-optimal feedback control of constrained nonlinear stochastic systems. In American Control Conference, 2005. Proceedings of the 2005, pp. 300–306. IEEE, 2005.
- Todorov et al. (2012) Todorov, Emanuel, Erez, Tom, and Tassa, Yuval. Mujoco: A physics engine for model-based control. In Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ International Conference on, pp. 5026–5033. IEEE, 2012.
- Weber et al. (2017) Weber, Theophane, Racanière, Sébastien, Reichert, David P., Buesing, Lars, Guez, Arthur, Rezende, Danilo Jimenez, Badia, Adrià Puigdomènech, Vinyals, Oriol, Heess, Nicolas, Li, Yujia, Pascanu, Razvan, Battaglia, Peter, Silver, David, and Wierstra, Daan. Imagination-augmented agents for deep reinforcement learning. CoRR, abs/1707.06203, 2017.
Appendix A Appendix
a.1 Training details for Gridworld tasks
a.2 Spaceship Environment
The state representation at each timestep consists of the concatenation of the following vectors:
where are the 2D position vectors of the spaceship, planet and waypoints respectively; is the velocity of the spaceship, and are the radii of the spaceship, planet and waypoints. At each timestep, the force of gravity applied to the spaceship is computed as:
where , and . Acceleration is then computed as
where is a damping constant and is the 2D thrust vector (a continuous action given by the agent). Position and velocity are then updated using a simulation step size of :
a.3 Training details for spaceship task
The forward model consisted of a state encoder, a state predictor and a reward predictor, which were all 2-layer MLPs with 512 hidden units and PReLU activations, as well as a linear action encoder which was added to the state encoding. The model was trained using Adam with learning rate 0.0001. We unrolled the forward model for 40 timesteps, providing it only the initial state in addition to the action sequence so that it used its predictions as subsequent state inputs as shown in Figure 1. This makes the learning problem much more challenging and helps encourage the model to be robust to its previous prediction errors. During inference, GBP performed 20 gradient steps with 20 rollouts. These same hyperparameters were used to generate the trajectories DistGBP was trained on.
As a policy network for DistGBP , we used a 4-layer MLP with 512 hidden units and ReLU activations with two heads: a softmax over actions and a linear layer mapping to 2D continuous actions. This is the same network architecture as the actor network in the A2C model.
Source: https://deepai.org/publication/model-based-planning-in-discrete-action-spaces
0 Response to "Model based Planning With Discrete and Continuous Actions"
Post a Comment